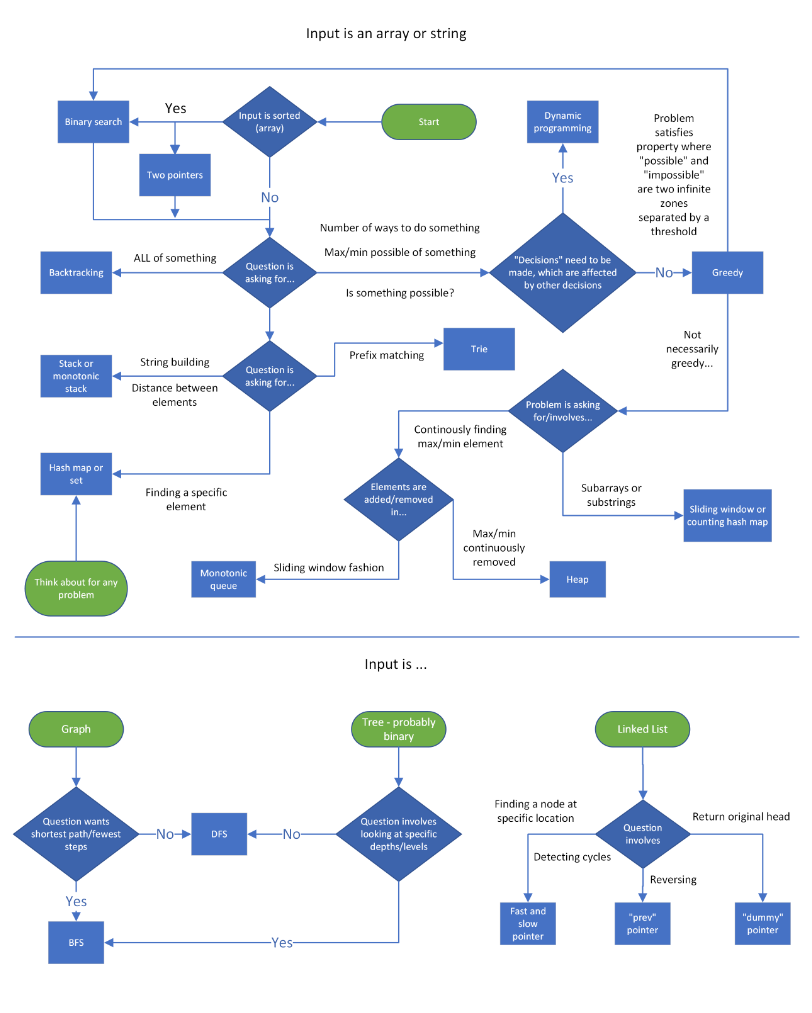
Cheatsheets
Введение в сложность времени выполнения операций
Сначала давайте обсудим временную сложность общих операций, разделенных по структурам данных/алгоритмам. Затем поговорим о разумных сложностях, учитывая размеры входных данных.
Массивы (динамический массив/список)
Дано n = arr.length:
- Добавление или удаление элемента в конце: O(1) амортизированное
- Добавление или удаление элемента из произвольного индекса: O(n)
- Доступ или модификация элемента по произвольному индексу: O(1)
- Проверка наличия элемента: O(n)
- Два указателя: O(n⋅k), где k — работа, выполняемая на каждой итерации, включает скользящее окно
- Построение префиксной суммы: O(n)
- Поиск суммы подмассива по префиксной сумме: O(1)
Строки (неизменяемые)
Дано n = s.length:
- Добавление или удаление символа: O(n)
- Доступ к элементу по произвольному индексу: O(1)
- Конкатенация двух строк: O(n+m), где m — длина другой строки
- Создание подстроки: O(m), где m — длина подстроки
- Два указателя: O(n⋅k), где k — работа, выполняемая на каждой итерации, включает скользящее окно
- Построение строки из объединения массива, stringbuilder и т.д.: O(n)
Связанные списки
Дано n — количество узлов в связанном списке:
- Добавление или удаление элемента при наличии указателя до места добавления/удаления: O(1)
- Добавление или удаление элемента при наличии указателя на место добавления/удаления: O(1) если двусвязный
- Добавление или удаление элемента в произвольной позиции без указателя: O(n)
- Доступ к элементу в произвольной позиции без указателя: O(n)
- Проверка наличия элемента: O(n)
- Обратный обход между позициями i и j: O(j−i)
- Обнаружение цикла: O(n) с использованием быстрых-медленных указателей или хэш-таблицы
Хэш-таблица/словарь
Дано n = dic.size:
- Добавление или удаление пары ключ-значение: O(1)
- Проверка наличия ключа: O(1)
- Проверка наличия значения: O(n)
- Доступ или модификация значения, связанного с ключом: O(1)
- Итерация по всем ключам, значениям или обоим: O(n)
Примечание: операции O(1) являются константными относительно n. На практике алгоритм хэширования может быть дорогим. Например, если ваши ключи — строки, то это будет стоить O(m), где m — длина строки. Операции занимают постоянное время относительно размера хэш-таблицы.
Множество
Дано n = set.size:
- Добавление или удаление элемента: O(1)
- Проверка наличия элемента: O(1) Это же примечание применяется здесь.
Стек
Операции стека зависят от их реализации. Стек должен поддерживать только pop и push. Если реализован с помощью динамического массива:
Дано n = stack.length:
- Добавление элемента: O(1)
- Удаление элемента: O(1)
- Peek (просмотр элемента на вершине стека): O(1)
- Доступ или модификация элемента по произвольному индексу: O(1)
- Проверка наличия элемента: O(n)
Очередь
Операции очереди зависят от их реализации. Очередь должна поддерживать только dequeue и enqueue. Если реализована с помощью двусвязного списка:
Дано n = queue.length:
- Добавление элемента: O(1)
- Удаление элемента: O(1)
- Peek (просмотр элемента в начале очереди): O(1)
- Доступ или модификация элемента по произвольному индексу: O(n)
- Проверка наличия элемента: O(n)
Примечание: большинство языков программирования реализуют очереди более сложным образом, чем простой двусвязный список. В зависимости от реализации доступ к элементам по индексу может быть быстрее, чем O(n), или O(n), но с значительным постоянным делителем.
Задачи с бинарным деревом (DFS/BFS)
Дано n — количество узлов в дереве:
Большинство алгоритмов будут работать за O(n⋅k), где k — работа, выполняемая на каждом узле, обычно O(1). Это общее правило и не всегда так. Мы предполагаем, что BFS реализовано с эффективной очередью.
Бинарное дерево поиска
Дано n — количество узлов в дереве:
- Добавление или удаление элемента: O(n) в худшем случае, O(logn) в среднем случае
- Проверка наличия элемента: O(n) в худшем случае, O(logn) в среднем случае
- Средний случай — это когда дерево хорошо сбалансировано, каждая глубина близка к полной.
- Худший случай — когда дерево представляет собой просто прямую линию.
Куча/Приоритетная очередь
Дано n = heap.length и говорим о минимальных кучах:
- Добавление элемента: O(logn)
- Удаление минимального элемента: O(logn)
- Поиск минимального элемента: O(1)
- Проверка наличия элемента: O(n)
- Бинарный поиск
- Бинарный поиск работает за O(logn) в худшем случае, где n — размер вашего начального пространства поиска.
Разное
- Сортировка: O(n⋅logn), где n — размер данных для сортировки
- DFS и BFS на графе: O(n⋅k+e), где n — количество узлов, e — количество ребер, если каждый узел обрабатывается за O(1) кроме итерации по ребрам
- Временная сложность DFS и BFS: обычно O(n), но если это граф, может быть O(n+e) для хранения графа
- Временная сложность динамического программирования: O(n⋅k), где n — количество состояний, а k — работа, выполняемая в каждом состоянии
- Пространственная сложность динамического программирования: O(n), где n — количество состояний
Размеры входных данных и временная сложность
Ограничения задачи можно рассматривать как подсказки, потому что они указывают верхнюю границу на то, какой должна быть временная сложность вашего решения. Умение определять ожидаемую временную сложность решения, учитывая размер входных данных, является ценной навыком. Во всех задачах LeetCode и большинстве онлайн-оценок (OA) вам будут даны ограничения задачи.
К сожалению, на собеседовании вам обычно не будут явно сообщать ограничения задачи, но это все равно полезно для практики на LeetCode и прохождения онлайн-оценок. Тем не менее, на собеседовании обычно не повредит спросить о ожидаемых размерах входных данных.
n <= 10
Ожидаемая временная сложность, вероятно, имеет факториальную или экспоненциальную сложность с основанием больше 2 — O(n^2 ⋅ n!) или O(4^n), например.
Следует подумать о обратном отслеживании или любом рекурсивном алгоритме с грубой силой. n <= 10 — это очень маленькое значение, и обычно любой алгоритм, который правильно находит ответ, будет достаточно быстрым.
10 < n <= 20
Ожидаемая временная сложность, вероятно, включает O(2^n). Любое большее основание или факториальная сложность будут слишком медленными (3^20 = ~3.5 миллиарда, а 20! гораздо больше). `2^n`` обычно подразумевает, что для коллекции элементов вы рассматриваете все подмножества/подпоследовательности — для каждого элемента есть два выбора: взять его или нет.
Опять же, это очень маленькое значение, поэтому большинство алгоритмов, которые правильны, вероятно, будут достаточно быстрыми. Рассмотрите обратное отслеживание и рекурсию.
20 < n <= 100
На этом этапе экспоненциальные алгоритмы будут слишком медленными. Верхняя граница, вероятно, будет включать O(n^3).
Задачи, помеченные как "легкие" на LeetCode, обычно имеют эту границу, что может быть обманчивым. Возможно, существуют решения, работающие за O(n), но маленькая граница позволяет пройти решениям с грубой силой (поиск линейного времени решения может не считаться "легким").
Рассмотрите решения с грубой силой, включающие вложенные циклы. Если вы придумаете решение с грубой силой, попробуйте проанализировать алгоритм, чтобы найти, какие шаги "медленные", и попытайтесь улучшить эти шаги с помощью инструментов, таких как хэш-таблицы или кучи.
100 < n <= 1,000
В этом диапазоне квадратичная временная сложность O(n^2) должна быть достаточной, пока постоянный множитель не слишком велик.
Аналогично предыдущему диапазону, вы должны рассматривать вложенные циклы. Разница между этим диапазоном и предыдущим заключается в том, что O(n^2) обычно является ожидаемой/оптимальной временной сложностью в этом диапазоне, и может быть невозможно улучшить.
1,000 < n < 100,000
n <= 10^5 — это наиболее распространенное ограничение, которое вы увидите на LeetCode. В этом диапазоне самой медленной допустимой общей временной сложностью является O(n⋅logn), хотя обычно целью является линейный подход O(n).
В этом диапазоне спросите себя, может ли быть полезно сортировать входные данные или использовать кучу. Если нет, то стремитесь к алгоритму O(n). Вложенные циклы, работающие за O(n^2), неприемлемы — вам, вероятно, потребуется использовать технику, изученную на этом курсе, чтобы имитировать поведение вложенного цикла за O(1) или O(logn):
- Хэш-таблица
- Реализация с двумя указа�телями, как скользящее окно
- Монотонный стек
- Бинарный поиск
- Куча
- Комбинация любого из вышеперечисленного
Если у вас есть алгоритм O(n), постоянный множитель может быть разумно большим (около 40). Обычная тема для задач с строками включает итерацию по символам алфавита на каждой итерации, что приводит к временной сложности O(26n).
100,000 < n < 1,000,000
n <= 10^6 — это редкое ограничение, и, вероятно, потребует временной сложности O(n). В этом диапазоне O(n⋅logn) обычно безопасен, если имеет небольшой постоянный множитель. Вы, вероятно, должны включить хэш-таблицу каким-то образом.
1,000,000 < n
С огромными входными данными, обычно в диапазоне 10^9 или более, наиболее распространенной допустимой временной сложностью будет логарифмическая O(logn) или постоянная O(1). В этих задачах вы должны либо значительно уменьшить свое пространство поиска на каждой итерации (обычно бинарный поиск), либо использовать хитрые трюки для поиска информации за постоянное время (например, с помощью математики или хитрого использования хэш-таблиц).
Другие временные сложности возможны, такие как O(n), но это очень редко и обычно встречается только в очень сложных задачах.
Как выбрать решение?