Подсчет
Подсчёт (Counting) — это очень распространённый шаблон использования hash maps (хэш-таблиц). Под "подсчётом" мы подразумеваем отслеживание частоты появления определённых элементов. Это означает, что наша hash map будет отображать ключи в целые числа (integers). Всякий раз, когда вам нужно что-то подсчитать, подумайте о том, чтобы использовать hash map для этого.
Напомним, что когда мы рассматривали алгоритмы с использованием скользящего окна (sliding windows), некоторые задачи имели ограничение на количество определённых элементов в окне. Например, самая длинная подстрока с не более чем k нулями (longest substring with at most k 0s).
В таких задачах мы могли просто использовать целочисленную переменную curr, так как мы фокусировались только на одном элементе (например, нам был важен только 0). Hash map открывает возможности для решения задач, где ограничения связаны с несколькими элементами. Давайте начнём с примера скользящего окна, в котором используется hash map.
Обычный подсчет появления элементов
https://leetcode.com/problems/longest-substring-with-at-most-k-distinct-characters/description/
https://github.com/doocs/leetcode/blob/main/solution/0300-0399/0340.Longest%20Substring%20with%20At%20Most%20K%20Distinct%20Characters/README_EN.md
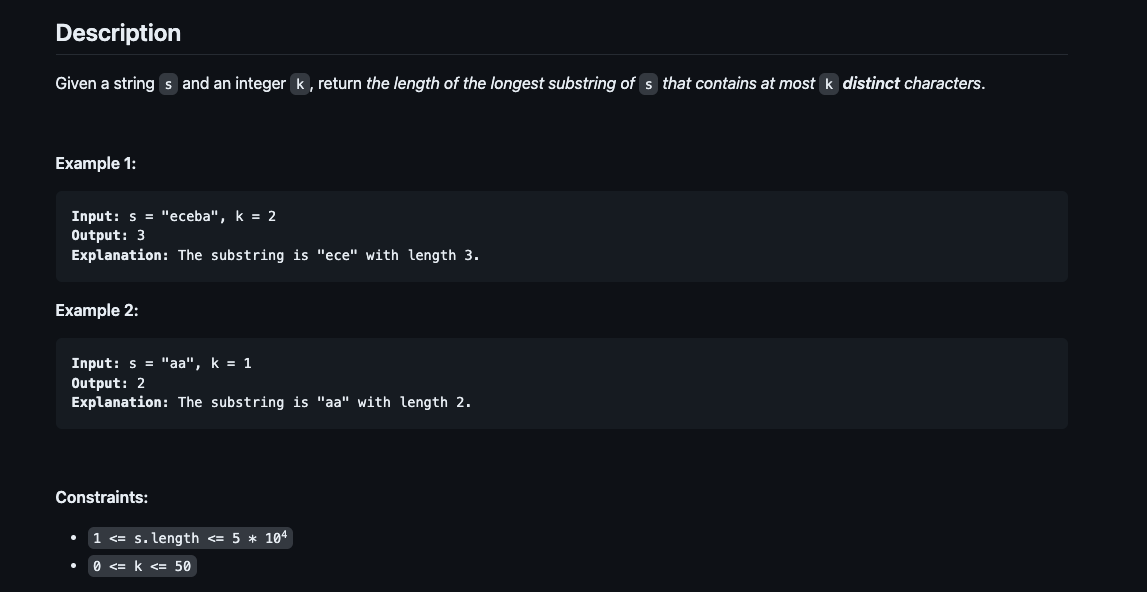
Эта задача касается подстрок (substrings) и имеет ограничение на количество различных символов в подстроке (at most k distinct characters). Эти характеристики подсказывают нам, что следует рассмотреть использование алгоритма скользящего окна (sliding window). Напомним, что идея скользящего окна заключается в том, чтобы добавлять элементы, сдвигая окно вправо, пока оно не нарушит ограничение. Как только это происходит, мы уменьшаем окно с левой стороны, пока оно снова не станет соответствовать ограничению. В данной задаче нас интересует количество различных символов в окне. Прямолинейный способ проверки этого ограничения заключался бы в проверке всего окна каждый раз, что могло бы занять O(n) времени. Используя hash map (хэш-таблицу), мы можем проверять это ограничение за O(1) времени.
Давайте используем hash map counts, чтобы отслеживать количество символов в окне. Это означает, что мы будем сопоставлять буквы с их частотой. Длина (количество ключей) counts в любой момент времени соответствует количеству различных символов. Когда мы удаляем символы с левой стороны, мы можем уменьшать частоту удаляемых элементов. Когда частота становится равной 0, мы знаем, что этот символ больше не является частью окна, и можем удалить ключ.
let findLongestSubstring = (s, k) => {
let counts = new Map();
let ans = 0;
let left = 0;
for (let right = 0; right < s.length; right++) {
counts.set(s[right], (counts.get(s[right]) || 0) + 1);
while (counts.size > k) {
counts.set(s[left], counts.get(s[left]) - 1);
if (counts.get(s[left]) == 0) {
counts.delete(s[left]);
}
left++;
}
ans = Math.max(ans, right - left + 1);
}
return ans;
};
Закрепить знания
- https://leetcode.com/problems/intersection-of-multiple-arrays/description/
- https://leetcode.com/problems/check-if-all-characters-have-equal-number-of-occurrences/description/
Подсчет массивов с точным ограничением
В статье про скользящее окно (sliding window) мы обсуждали шаблон "найти количество подмассивов/подстрок, которые соответствуют ограничению". В тех задачах, если у вас было окно между left и right, которое соответствовало ограничению, тогда все окна от x до right также соответствовали бы этому ограничению, где left < x <= right.
Для этого шаблона мы будем рассматривать задачи с более строгими ограничениями, где упомянутое свойство не обязательно будет выполняться.
Например, задачу "Найти количество подмассивов, сумма которых меньше k" с входными данными, содержащими только положительные числа, можно было бы решить с использованием скользящего окна.
Но как "Найти количество подмассивов, сумма которых точно равна k".
Сначала некоторые из этих задач могут показаться очень сложными. Однако, шаблон очень прост, как только вы его усвоите, и вы увидите, насколько похож код для каждой задачи, попадающей в этот шаблон. Чтобы понять алгоритм, нужно вспомнить концепцию префиксных сумм (prefix sums).
С помощью префиксной суммы можно найти сумму подмассивов, взяв разность между двумя префиксными суммами. Допустим, вы хотите найти подмассивы с суммой, точно равной k, и у вас уже есть префиксная сумма для входных данных. Вы знаете, что любая разность префиксных сумм, равная k, представляет собой подмассив с суммой, равной k. Как же найти эти разности?
Сначала давайте объявим hash map counts, который будет отображать префиксные суммы в частоты их появления (число может появляться несколько раз в префиксной сумме, если во входных данных есть отрицательные числа, например, если nums = [1, -1, 1], то префиксная сумма будет [1, 0, 1], и 1 появляется дважды). Нам нужно инициализировать counts[0] = 1. Это потому, что пустой префикс [] имеет сумму 0. Скоро вы увидите, почему это необходимо.
let fn = (arr, k) => {
let counts = new Map();
counts.set(0, 1);
let ans = 0,
curr = 0;
for (const num of arr) {
// do logic to change curr
ans += counts.get(curr - k) || 0;
counts.set(curr, (counts.get(curr) || 0) + 1);
}
return ans;
};
Далее давайте объявим переменные для ответа (answer) и текущей суммы (curr). По мере итерации по входным данным curr будет представлять сумму всех элементов, которые мы уже прошли (сумму текущего префикса).
Теперь мы начинаем итерацию по входным данным. На каждом элементе мы обновляем curr и поддерживаем counts, увеличивая частоту curr на 1. Однако, прежде чем обновить counts, мы сначала должны обновить наш answer.
Как обновить answer? Напомним, что в статье про скользящее окно, когда мы искали "количество подмассивов", мы сосредоточились на каждом индексе и выясняли, сколько допустимых подмассивов заканчивается на текущем индексе. Мы будем делать то же самое здесь. Предположим, что мы находимся на индексе i. До этого момента мы знаем, что curr хранит префикс всех элементов до i. Мы также знаем, что все другие префиксы до i были сохранены в counts. Поэтому, если подмассив заканчивается на i с суммой k, то префикс curr - k должен был встретиться ранее.
Напомним, что сумма подмассива находилась путем вычитания двух префиксов. Если curr - k существовал как префикс до этого момента, и наш текущий префикс равен curr, тогда раз�ность между этими двумя префиксами равна curr - (curr - k) = k, что и является тем, что мы ищем.
Таким образом, мы можем увеличить наш answer на значение counts[curr - k]. Если префикс curr - k встречался несколько раз до этого (из-за отрицательных чисел), тогда каждый из этих префиксов может быть использован как начальная точка для формирования подмассива, заканчивающегося на текущем индексе с суммой k. Вот почему нам нужно отслеживать частоту.
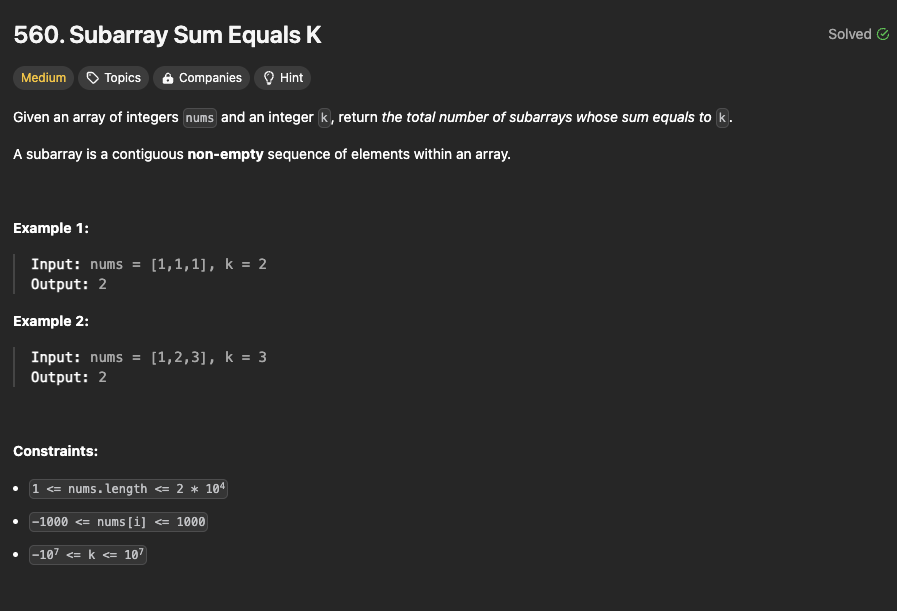
Пример
https://leetcode.com/problems/subarray-sum-equals-k/description/
var subarraySum = function (nums, k) {
let count = new Map();
count.set(0, 1);
let ans = 0;
let curr = 0;
for (const num of nums) {
curr += num;
ans += count.get(curr - k) || 0;
count.set(curr, (count.get(curr) || 0) + 1);
}
return ans;
};
Закрепить знания
- https://leetcode.com/problems/subarray-sum-equals-k/description/
- https://leetcode.com/problems/find-players-with-zero-or-one-losses/description/
- https://leetcode.com/problems/contiguous-array/description/
Общие задачи по теме
- https://leetcode.com/problems/sum-of-unique-elements/description/
- https://leetcode.com/problems/unique-number-of-occurrences/description/
- https://leetcode.com/problems/permutation-in-string/description/
- https://leetcode.com/problems/maximum-erasure-value/description/
- https://leetcode.com/problems/binary-subarrays-with-sum/description/