Теория
Граф — это любая совокупность узлов и связей между этими узлами.
Узлы графа также называются вершинами, а указатели, которые их соединяют, называются ребрами. В графических представлениях узлы/вершины обычно изображаются кругами, а ребра - линиями/стрелками, соединяющими круги (мы видели это в главе о связанных списках).
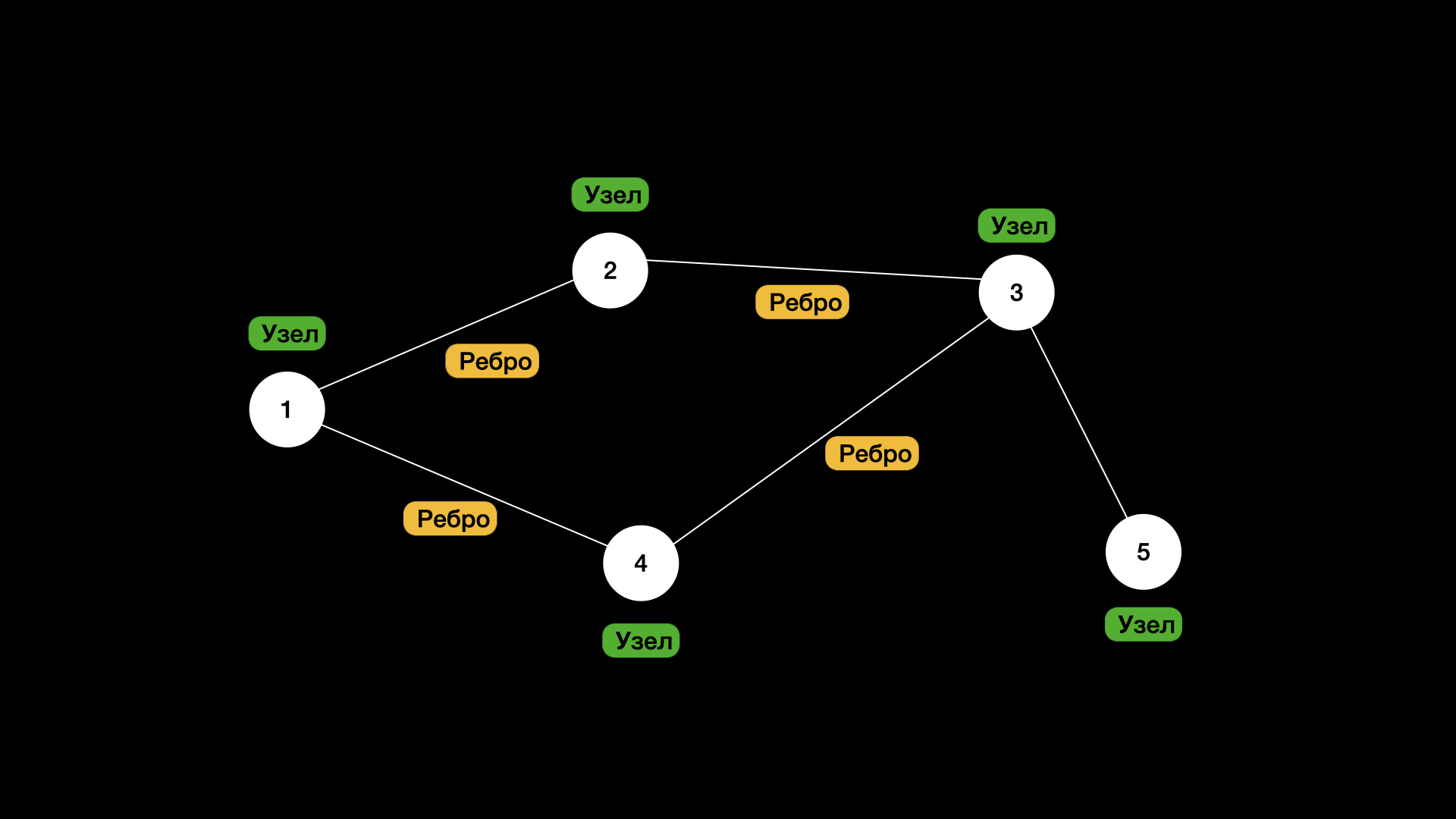
Но в отличие от бинарных деревьев, у нас нет ограничений на количество исходящих и входящих связей. Граф - это топологическая модель. Или говоря проще, мы рассматриваем граф не с точки зрения точного расположения вершин и длин рёбер, а с точки зрения того, какие вершины связаны между собой. То есть важна именно структура связей, а не геометрические детали. Если перерисовать граф, изменив расположение вершин, но оставив связи пре�жними, его топологические свойства останутся неизменными.
Терминология графов
Далее будет предложена самая необходимая терминология для решения задач во время интервью. Теория графов невероятно большая и имеет под собой большую математическую базу. Рассмотрением этой базы данный раздел курса не занимается на сегодняшний день.
Рёбра узла могут быть либо ориентированными, либо неориентированными (directed or undirected). Ориентированные рёбра означают, что перемещение возможно только в одном направлении. Если вы находитесь в узле A и существует ориентированное ребро к узлу B, вы можете переместиться из A в B, но оказавшись в B, вы не сможете вернуться из B в A. В графических представлениях ориентированные рёбра изображаются стрелками между узлами. Неориентированные рёбра означают, что можно перемещаться в обоих направлениях. Используя тот же пример, можно перемещаться как из A в B, так и из B в A. В графических представлениях неориентированные рёбра обычно изображаются прямыми линиями между узлами.
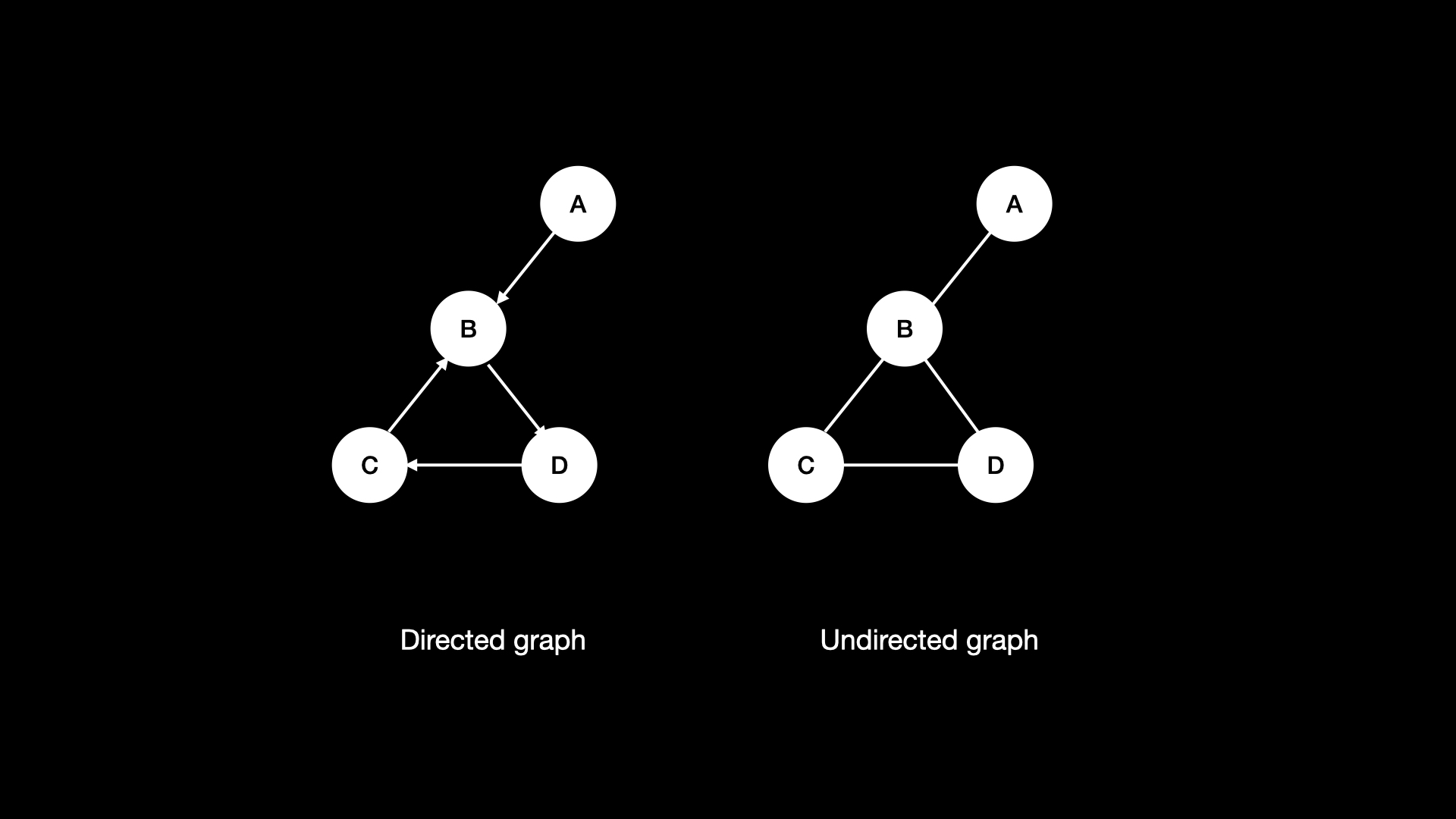
В бинарных деревьях рёбра были ориентированными. Бинарные деревья — это ориентированные графы. Вы не можете получить доступ к родительскому узлу, а только к его детям. Как только вы перемещаетесь к ребёнку, вы не можете вернуться назад.
Другой важный термин — связная компонента (connected component). Связная компонента графа — это группа узлов, соединённых рёбрами.
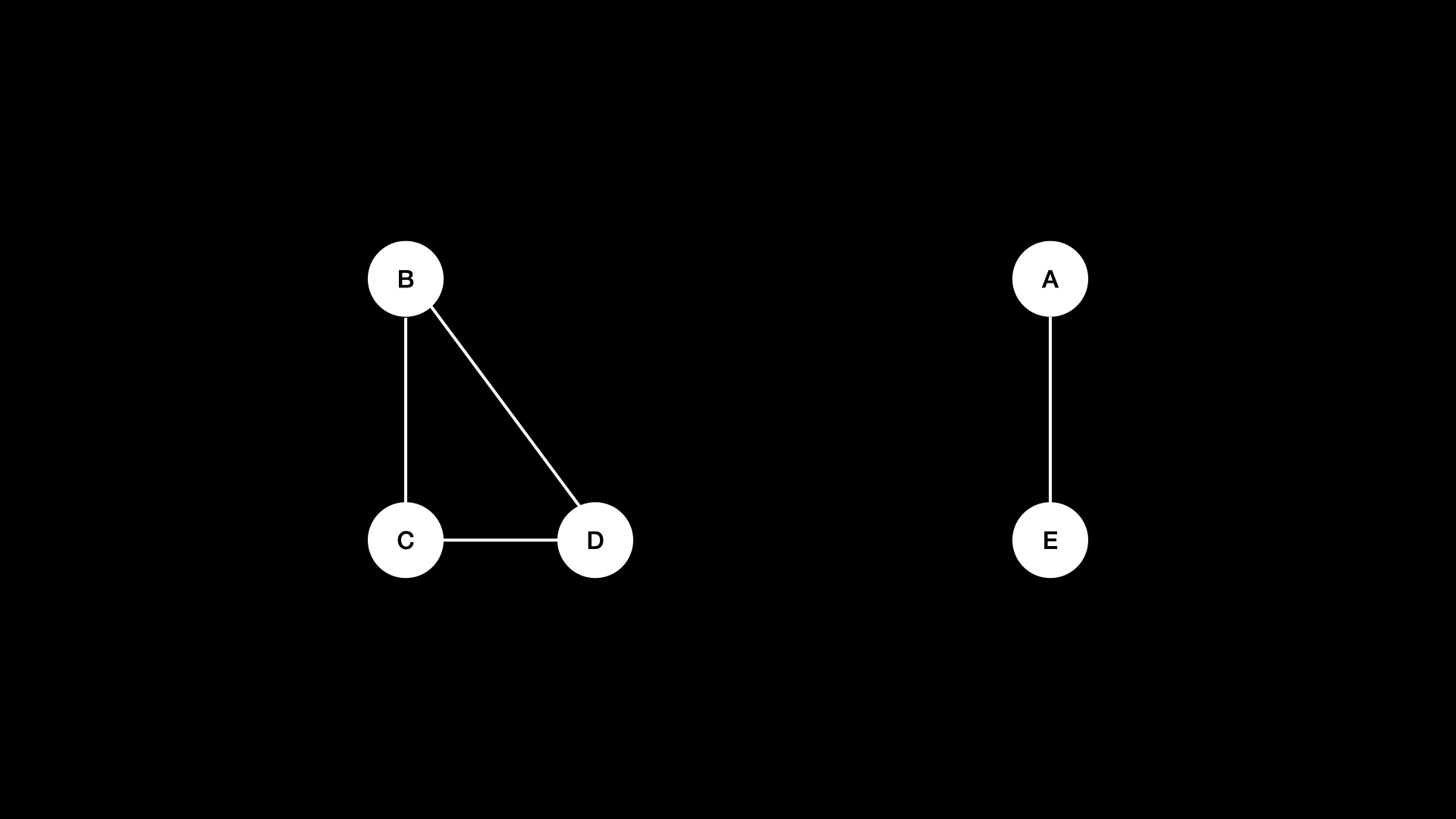
В бинарных деревьях должна быть только одна связная компонента (все узлы достижимы из корня).
Узел может иметь любое количество рёбер, соединённых с ним. Если у нас есть ориентированный граф,
он может иметь любое количество входящих и исходящих рёбер. Количество рёбер, с помощью которых можно
добраться до узла, называется входной степенью узла (indegree). Количество рёбер, с помощью которых можно покинуть
узел, называется исходной степенью узла (outdegree). Узлы, соединённые ре�бром, называются соседями. Таким образом,
если у вас есть граф вида A <-> B <-> C, узел A является соседом узла B, узел B — соседом узлов A и C,
а узел C — соседом узла B.
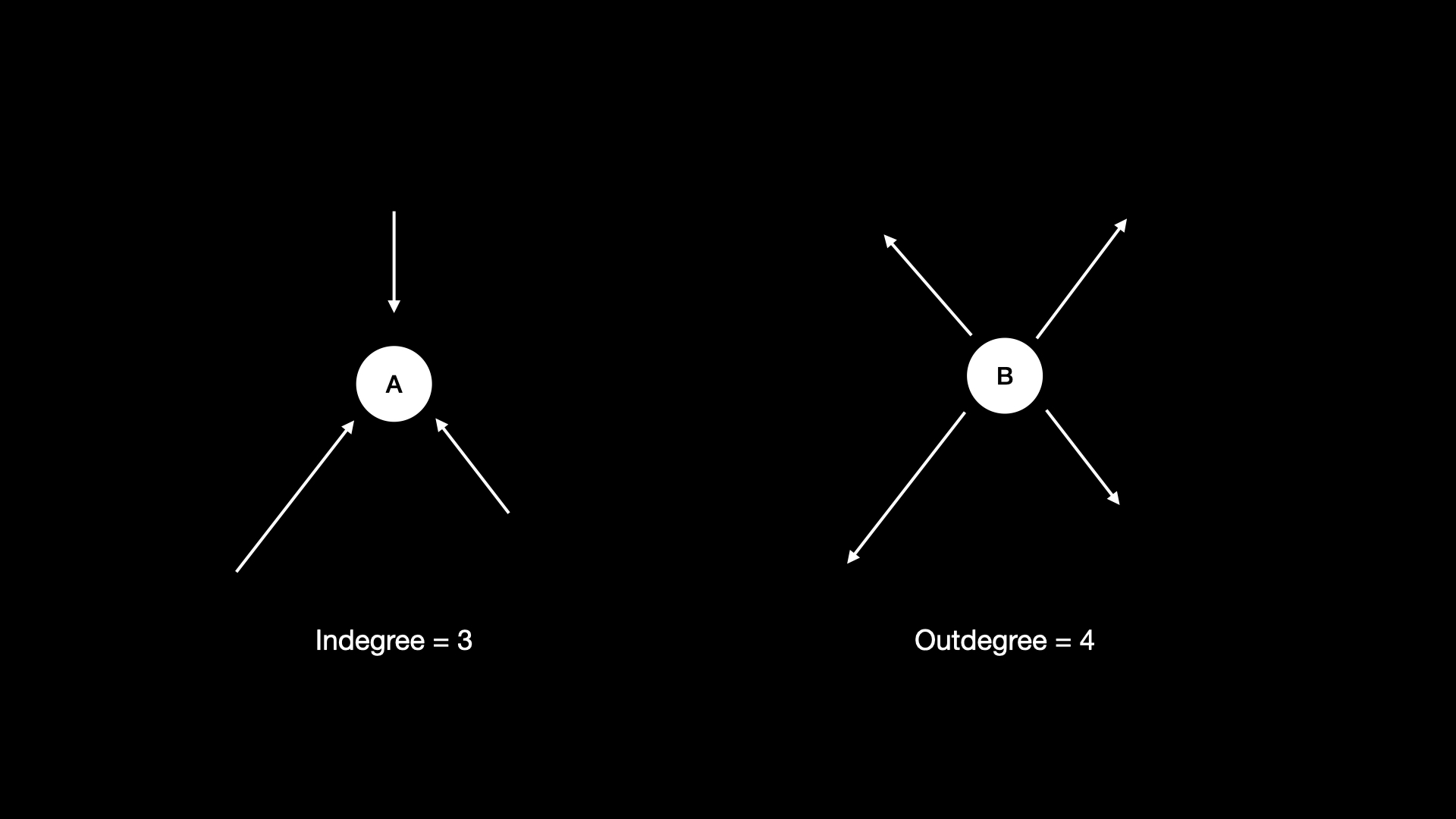
В бинарных деревьях все узлы, кроме корня, имели входную степень, равную 1 (из-за их родителя). Все узлы имеют исходную степень 0, 1 или 2. Исходная степень 0 означает, что узел является листом. В деревьях мы использовали термины «родитель/ребёнок» вместо «соседи».
Граф может быть циклическим (cyclic) или ациклическим (acyclic). Циклический означает, что в графе существует цикл, а ациклический — что цикла нет. Мы уже узнали, что такое цикл, в главе о связанных списках — это когда имеется путь по рёбрам, приводящий к бесконечному повторному посещению одних и тех же узлов.
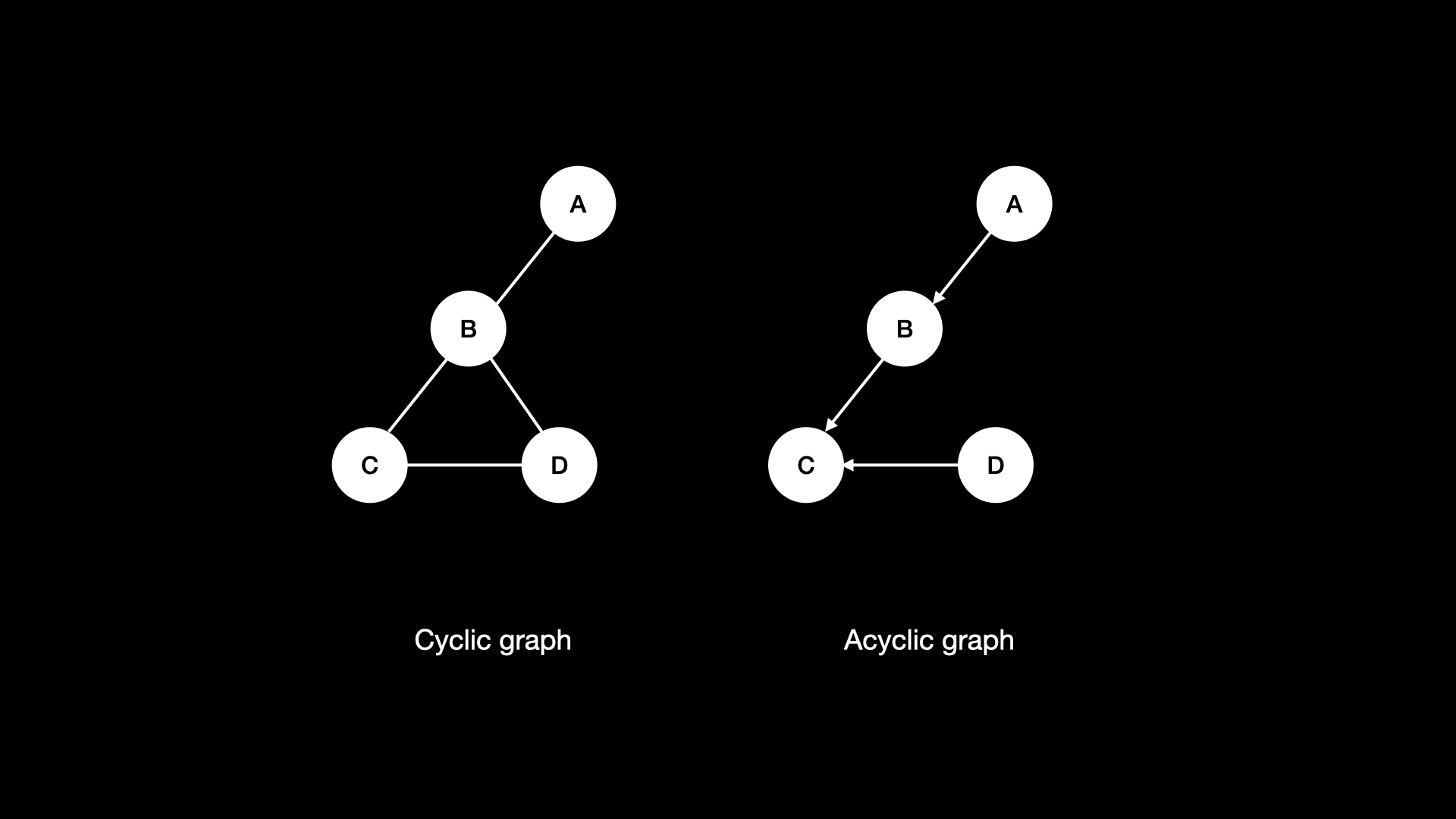
Форматы графов
Важно понимать, что в случае со связанными списками и бинарными деревьями вам буквально даются объекты в памяти, содержащие данные и указатели. С графами же всё устроено иначе: граф в памяти не существует буквально.
На самом деле, имеется только «идея» графа. Входные данные дают некоторую информацию о нём, и от вас зависит, как вы представите граф и организуете его обход в коде.
Часто узлы графа нумеруются от 0 до n - 1. В условии задачи может прямо не указываться, что входные данные представляют граф. Иногда присутствует история, и вам необходимо понять, что речь идёт о графе. Например: «есть n городов, пронумерованных от 0 до n - 1». Вы можете считать каждый город узлом, а его номер — уникальной меткой.
С бинарными деревьями обход был прост, потому что для любого узла нужно было ссылаться только на его node.left и
node.right. Это позволяло сосредоточиться исключительно на самом обходе (с использованием DFS или BFS). В графах
же узел может иметь любое количество соседей. Прежде чем начать обход, обычно требуется выполнить некоторую
подготовительную работу, чтобы для любого узла можно было сразу получить доступ ко всем его соседям.
Первый формат входных данных - массив рёбер (array of edges)
В этом формате входные данные представляют собой двумерный массив. Каждый элемент массива имеет вид [x, y], что
указывает на наличие ребра между x и y. В условии задачи может быть описана история этих рёбер — используя пример с
городами, история могла бы звучать так: «[x, y] означает, что существует шоссе, соединяющее город x и город y».
graph = [
[0, 1],
[1, 2],
[2, 0],
[2, 3],
];
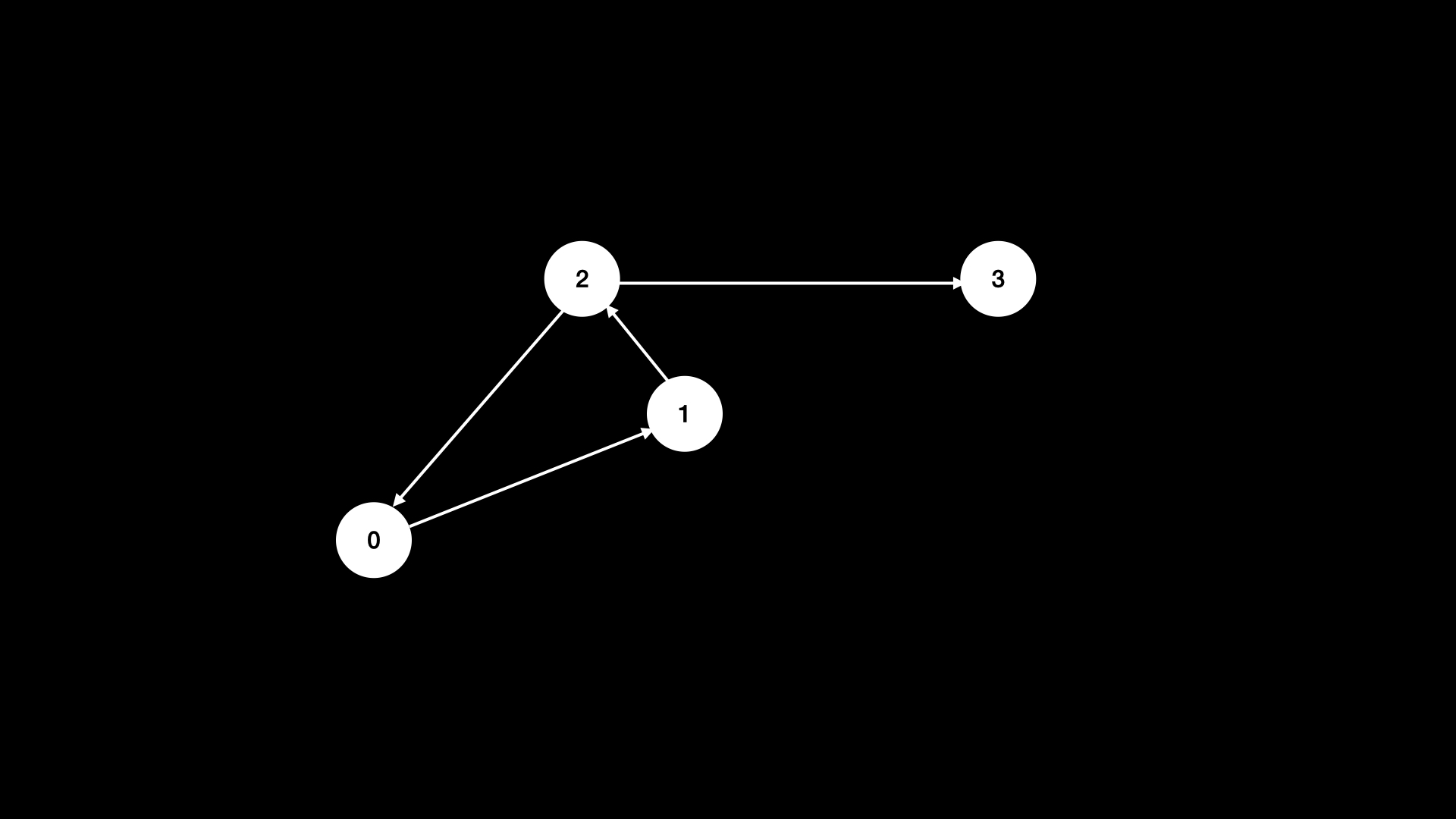
Рёбра могут быть ориентированными или неориентированными. Эта информация будет указана в описании задачи.
Почему же нельзя сразу начать обход? Предположим, мы хотим начать поиск в глубину (DFS) с узла 0 (иногда задача указывает, с какого узла начать, а иногда это приходится определять самому). Когда мы находимся в узле 0, как найти его соседей? Необходимо перебрать весь входной массив, чтобы найти все рёбра, содержащие 0. При переходе к соседнему узлу придётся снова перебирать все входные данные, чтобы найти его соседей.
На ка�ждом узле потребуется проходить по всему массиву входных данных для поиска соседей. Это очень медленно!
Перед началом обхода можно предварительно обработать входные данные так, чтобы можно было легко находить всех соседей для любого узла. Идеально, если использовать структуру данных, позволяющую по узлу получить список его соседей. Самый простой способ — использовать хеш-таблицу.
Предположим, у вас есть хеш-таблица graph, которая сопоставляет целые числа со списками целых чисел. Мы можем
пройтись по входным данным и для каждой пары [x, y] добавить y в список, ассоциированный с graph[x]. Если рёбра
неориентированные, нужно также добавить x в список, ассоциированный с graph[y]. После построения этой хеш-таблицы
можно выполнить запрос graph[0] и сразу получить всех соседей узла 0.
Представьте, что вы на Facebook и хотите увидеть список всех своих друзей. Но инженеры Facebook решили хранить их граф в виде массива рёбер! Вам пришлось бы просматривать каждое соединение в мире (а их, скорее всего, сотни миллиардов, если не триллионы) и искать те, которые вас касаются. Однако, если граф построен заранее, вы можете просто нажать на вкладку друзей в своём профиле и увидеть только своих друзей.
Этот пример графа может быть представлен в виде массива ориентированных рёбер. Обратите внимание, что граф на изображении не существует в памяти. Он существует лишь как идея, выведенная из массива ориентированных рёбер.
let buildGraph = (edges) => {
let graph = new Map();
for (const [x, y] of edges) {
if (!graph.has(x)) {
graph.set(x, []);
}
graph.get(x).push(y);
}
};
Второй формат входных данных - список смежности (adjacency list)
В списке смежности узлы нумеруются от 0 до n - 1. Входные данные представлены в виде двумерного массива целых чисел,
который обозначается как graph. Элемент graph[i] — это список всех исходящих рёбер из i-го узла.
Обратите внимание, что с таким форматом входных данных мы можем сразу получить доступ �ко всем соседям любого узла без
предварительной обработки! Это делает список смежности наиболее удобным форматом. Если, например, нам нужны все
соседи узла 6, достаточно проверить graph[6].
graph = [[1], [2], [0, 3], []];
Третий формат входных данных - матрица смежности (adjacency matrix)
Следующий формат — матрица смежности. Снова узлы нумеруются от 0 до n - 1. Вам будет дана двумерная матрица размера
n x n, которую мы обозначим как graph. Если graph[i][j] == 1, это означает, что существует исходящее ребро от
узла i к узлу j.
adjacencyMatrix = [
[0, 1, 0, 0],
[0, 0, 1, 0],
[1, 0, 0, 1],
[0, 0, 0, 0],
];
При использовании этого формата у вас есть два варианта. Во время обхода, для любого узла, вы можете перебирать
graph[node], и если graph[node][i] == 1, то узел i является его соседом. Альтернативно, можно предварительно
обработать граф, как мы делали с массивом рёбер. Для этого создайте хеш-таблицу и пройдитесь по всей матрице.
Если graph[i][j] == 1, добавьте j в список, ассоциированный с узлом i. Таким образом, во время обхода вам не
придётся перебирать n элементов для поиска соседей. Это особенно полезно, когда у узлов немного соседей, а n велико.
Оба подхода имеют временную сложность O(n²).
Четвертый формат - матрица m * n (matrix)
Этот формат более тонкий, но очень распространён. Входные данные представляют собой двумерную матрицу, а в задаче обычно описывается некая история. Каждая ячейка матрицы будет что-то представлять, и эти ячейки как-то связаны между собой. Например: «Каждая ячейка матрицы — это деревня. Деревни торгуют со своими соседними деревнями, которые расположены прямо над ней, слева, справа или под ней».
В таком случае каждая ячейка (row, col) матрицы — это узел, а соседями будут (row - 1, col), (row, col - 1), (row + 1, col) и (row, col + 1) (при условии, что они не выходят за границы матрицы).
В отличие от других форматов входных данных, узлы в этих графах не нумеруются от 0 до n - 1. Вместо этого каждая ячейка в матрице представляет узел, а рёбра определяются описанием задачи, а не входными данными. В приведённом выше примере описание задачи указывает, что деревни торгуют с теми, кто находится непосредственно рядом. Значит, рёбра соединяют те деревни, которые находятся в соседних ячейках. Нужно внимательно анализировать условие, чтобы понять подобные графы.
Отличия в коде при работе с графами и деревьями
Существует несколько заметных различий между решением задач на графы и задач на бинарные деревья. В бинарном дереве у нас есть корень, с которого начинается обход. В графе же не всегда очевидно, с какого узла начинать.
В бинарном дереве мы получаем объекты для узлов, и в каждом узле есть указатель на его детей. В графе же зачастую
сначала нужно преобразовать входные данные в хеш-таблицу или другую структуру. При обходе дерева мы просто
используем node.left и node.right. При обходе графа приходится использовать цикл для перебора всех соседей
текущего узла, потому что у узла может быть любое количество соседей.
Реализация DFS для графов похожа на реализацию для деревьев. При рекурсивном подходе мы так же проверяем базовый случай, рекурсивно вызываем обход для всех соседей, обрабатываем некоторую логику и возвращаем результат. Можно также делать это итеративно, используя стек.
Однако, в любом неориентированном графе или ориентированном графе с циклами, если мы будем реализовывать DFS так же,
как в бинарном дереве, мы столкнёмся с бесконечным циклом (вспомните циклы в связанных списках: представьте, что ваш
код будет ходить по кругу бесконечно!). Как и в деревьях, в большинстве задач на графы мы хотим посетить каждый узел
ровно один раз. Чтобы избежать циклов и повторного посещения одного узла, мы используем множество seen. Перед тем
как посетить узел, мы проверяем, есть ли он в seen. Если нет, то добавляем его в seen и только потом посещаем.
Это позволяет посещать каждый узел ровно один раз за время O(1), так как добавление и проверка существования в
множестве занимают постоянное время.
В деревьях это не требовалось, потому что мы начинали с корня и двигались только «вниз» — покинув узел, невозможно
было к нему вернуться. В графах же может быть связь A <-> B, позволяющая перемещаться между A и B бесконечно.
Что касается выбора начального узла для обхода, это зависит от конкретной задачи и цели решения.
Это еще не все форматы
Иногда граф менее очевиден. Формат входных данных может не походить ни на один из перечисленных ранее. Помните, что граф — это любая абстрактная коллекция элементов (узлов), связанных некоторыми абстрактными отношениями рёбрами). Если в задаче речь идёт о переходах между состояниями, попробуйте представить эти состояния в качестве узлов, а критерии перехода — в качестве рёбер. Кроме того, если в задаче нужно найти кратчайший путь или минимальное количество операций и т.д., это отличный повод задуматься об использовании BFS.
https://leetcode.com/problems/contains-duplicate-ii/description/
var containsNearbyDuplicate = function (nums, k) {
const map = new Map();
for (let i = 0; i < nums.length; i++) {
if (map.has(nums[i])) {
const dist = i - map.get(nums[i]);
if (dist <= k) {
return true;
}
}
map.set(nums[i], i);
}
return false;
};